

Η τεχνητή νοημοσύνη DeepMind της Google έχει εξελιχθεί για να διαπρέπει σε περίπλοκα παιχνίδια, κερδίζοντας κορυφαίους παίκτες στον κόσμο. Το 2016 η AlphaGo AI κέρδισε τους καλύτερους παίκτες Go και ακολούθησε μία βελτιωμένη έκδοση η AlphaGo Zero. Αρχικά η Alpha Go βασίστηκε σε δεδομένα που περιλάμβαναν παρατήρηση επαγγελματικών και ερασιτεχνικών αγώνων και έπειτα η AlphaGo Zero βασίστηκε μόνο σε παιχνίδια που έπαιζε μόνη της. Το ίδιο έκανε και η AlphaZero, η οποία διέπρεψε σε Go, σκάκι και Shogi γνωρίζοντας μόνο τους κανόνες των παιχνιδιών.
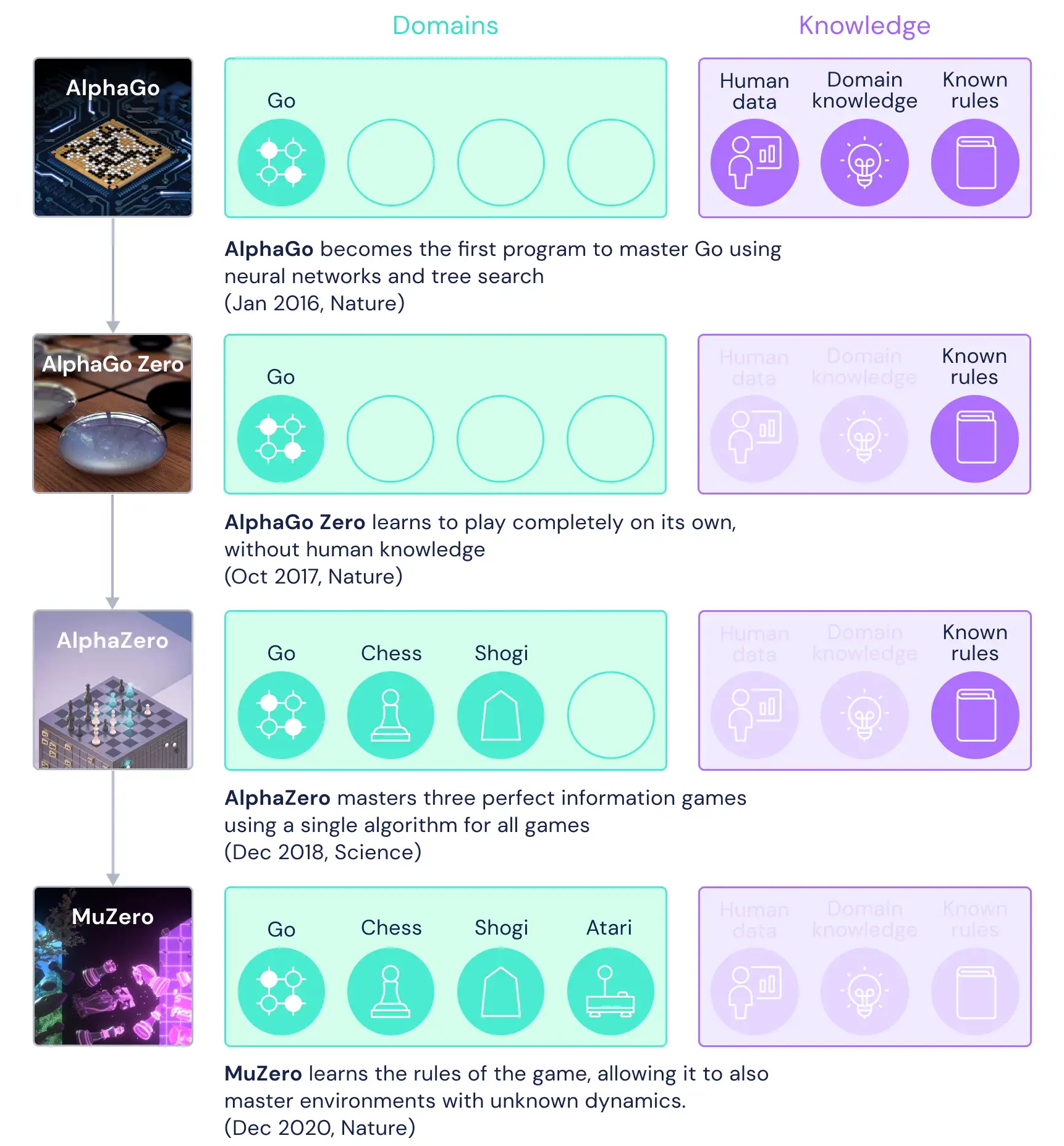
Η νέα εξέλιξη της DeepMind, η MuZero, δεν ξέρει τους κανόνες από πριν και μαθαίνει να αξιολογεί κάθε πληροφορία παρατηρώντας τι είναι σημαντικό και τι όχι. Μετά από ένα εκατομμύριο παιχνίδια, μαθαίνει όχι μόνο τους κανόνες αλλά και τη γενική αξία μίας θέσης ή μίας στρατηγικής.
Συστήματα που χρησιμοποιούν πρότερη γνώση, όπως η AlphaZero, έχουν πετύχει σημαντική πρόοδο σε κλασσικά παιχνίδια, αλλά βασίζονται στη γνώση της δυναμικής του περιβάλλοντος, όπως οι κανόνες του. Αυτό το κάνει δύσκολο να τις εφαρμόσεις σε περίπλοκα προβλήματα του πραγματικού κόσμου, τα οποία είναι συνήθως δύσκολα να τα ανάγεις σε απλούς κανόνες.

Κατανοώντας τον κόσμο του παιχνιδιού, η MuZero σχεδιάζει τις κινήσεις της ακόμα κι αν το παιχνίδι είναι περίπλοκα Atari games. Έτσι η MuZero μοιάζει περισσότερο με μία τεχνητή νοημοσύνη που μπορεί να αλληλεπιδράσει έξυπνα και με ασφάλεια με τον πραγματικό κόσμο, μαθαίνοντας να τον καταλαβαίνει χωρίς την ανάγκη να της εξηγούμε κάθε μικρή λεπτομέρεια.




Οι λεπτομέρειες της έρευνας της MuZero δημοσιεύθηκαν χτες στο Nature.
.webp)
Must Read

ΤΟ ΨΑΞΑΜΕ... | Πόσο συχνά μας δίνει λάθος απαντήσεις η ΑΙ;

ΕΚΤΑΚΤΟ: Αποσύρεται η πανίσχυρη AI Claude Fable 5 της Anthropic – Επέμβαση από την αμερικανική κυβέρνηση

Ο Microsoft Edge αναβαθμίζεται με τον Google λογαριασμό σας!
